SREcon EMEA 2019
This year the SREcon is located in Dublin. I attended the following talks:
The SRE I aspire to be
https://www.usenix.org/conference/srecon19emea/presentation/aknin
What is the meaning of SRE? The presenter suggested the following term: "Using scientific principles to build things." Whereas an imported part of scientific principles is measuring.
SRE is the art of measurably optimize reliability vs. cost. To do its job the Engineer has the following possibilities:
- Trade cost
- Trade quality
- Trade latency
And any of these trades add complexity.
The following reliability patterns exist:
- Watterfall
- Jitter
- Breaker
- Infrastructure as Code
- Partitioning
- Sidcar
- Fail State
- Self healing
SRE is the trade off between an Innovation and Reliability:
| Innovation | Reliability |
|---|---|
| engineering | support |
| procactive | reactive |
| change | preserve |
=> Measure it with Error Budget (Other measurements may be: MTBF/MTTF, 9s (e.g. 99% uptime)
SRE Team: a recipe
| Fundamental | Advanced | Pioneering |
|---|---|---|
| Monitoring | System Architecture | Product Management |
| Alerting | Distributed Algorithms | Data Science |
| Capacity Planning | Networking | Business Acumen |
| CI/CD & Rollouts | Operating System | US Research |
| Load Balancing |
Summary:
- Have a measurement of reliability
- The measurement is tied to project properties
- Your ops work is tied to the measurement
A systems approach to safefy and cyber security
A systems approach to safefy and cyber security
This talk was about appling already known concepts from complex machine engineering (aircraft, missel) to software systems.
The problem is that our tools are 50-60 years old, but our technology is different today. That results often in a broken or missing interaction between components. And our current tools doesn't allow us to focus on this interactions. This results in unsafe requirements.
Change in the way we conceive of human error:
- Traditional Approach:
- Operators responsible for most accidents
- So fire, train them not to make mistakes, or add more automation (which marginalizes the operator and causes more and different errors)
- Systems approach:
- Human behaviour always affected by the context in which it occurs
- We are designing systems in which human error is inevitable
- Human error is a symptom of a system that needs to be redesigned
- To eliminate human errors, need to change the system design
- Human behaviour always affected by the context in which it occurs
Summary:
- Safety and Reliability are not the same, but are overlapping
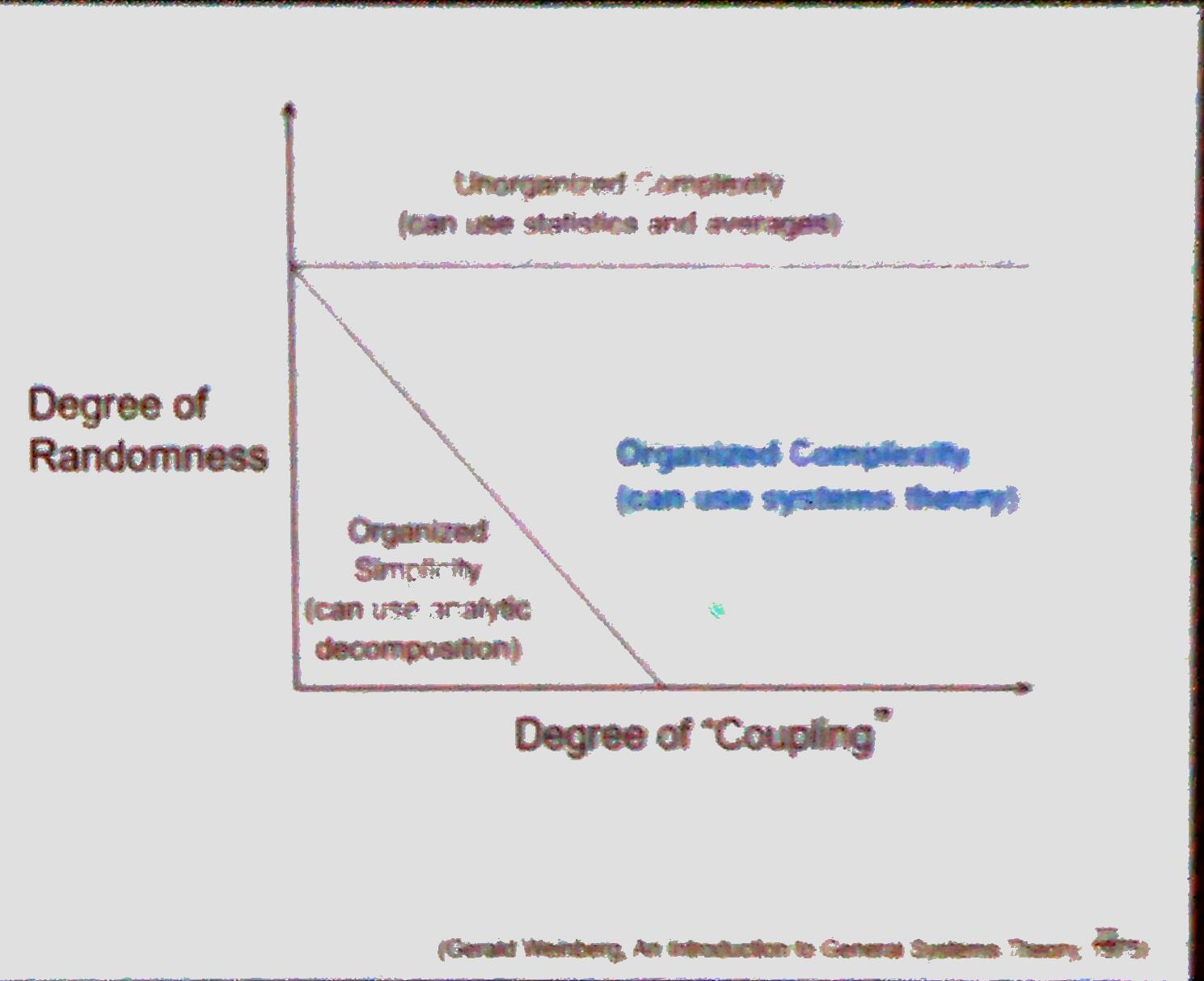
- Systems are too complex
- Traditional approach: Analytic decomposition (Device & Conquer)
- New approach: System Theory
- Treat safety as a control problem not a failure problem
Workshop: Automating HA Deployments with BGP, IPv6 and Anycast
Automating HA Deployments with BGP, IPv6, and Anycast
Link to the Lab description: BGP-Anycast-Workshop
The BGP and IPv6 stuff wasn't new to me. But the guys talked a little bit about the bare metal deployment at Packet and that was quite interesting.
- Prepopulated Hosts with most used Images
- PXE boot and image copiing in only 5 Minutes
- Packet has there own Terraform plugins, e.g. pulling IP addresses.
Workshop: Implementing Distributed Consensus
Implementing Distributed Consensus
Dan wrote his own application, skinny, to simulate a "hot potato" game. With this application the tried to teach himself distributed consensus (paxos). The application is written in go. For the workshop he set up a working environment with strigo: https://app.strigo.io/event/2AKwJWJ7XELsCSyu8
All relevant tools (also the deployment tools) are in his Gitlab Project: Skinny
Zero Touch Prod: Towards Safer and More Secure Production Environments
Zero Touch Prod: Towards Safer and More Secure Production Environments
The two guys from Google were talking about mitigating some typical outage scenarios. Here are some hints:
- never make a type
- with great power, comes great responsibility
- What can possibly happen
- wildcards
- no rate limiting
According to the Google engineers Zero touch prod (ZTP) would prevent 13% of all their outages. And the invest in ZTP would be less than the cost of the outages. These are the three areas of ZTP:
- Automation
- Limiting priviledge (principle of least priviledge)
- Enforcing safety policies: safety checks (a system should ask a "safety service" for allowence)
- Controlling the rate of change: rate limiting
- Safe proxies
- do not allow direct access to the services. All access should go through safe proxies
- Needs a break-glass switch for emergencies
- Adopt
- Define a set of metrics that classify your production safety criteria
Every change in production must be either made by automation, prevalidationed by Software od made via audited break-glass mechanism (Seth Hattich)
Fast, Available, Catastrophically Failing? Safely Avoiding Behavioral Incidents in Complex Production Systems
This was a fun, but strange talk. I don't really know how to summarize it. I try it anyway
1) Test in production - beyond release 2) Progressive delivery - CD with fine controls (Canary, feature flags) 3) Error Budget - Opportunity for learning
Three threads to reliability:
- Environment change
- Software change
- Data hazardous
A "behavioural outages" was defined as a situation where the result of processed data, results in an unwanted condition. As an example was mentioned, that Apple's Siri defned Bob Dylan as Dead (nevertheless he was still alive).
=> Data complexity replaces code complexitiy.
Talks I would have liked to attend, but hadn't the time for it
Here's a list of talks I couldn't attend but would have:
- Latency SLOs Done Right
- Building a Scalable Monitoring System
- A Tale of Two Rotations: Building a Humane & Effective On-Call
- Support Operations Engineering: Scaling Developer Products to the Millions
- The Unmonitored Failure Domain: Mental Health
- Eventually Consistent Service Discovery
- Network Monitor: A Tale of ACKnowledging an Observability Gap
- Zero-Downtime Rebalancing and Data Migration of a Mature Multi-Shard Platform